

Flat Circle - More information, lower accuracy?
Plus: Two research papers, 7 upcoming earnings, another system upgrade

Flat Circle measures the ability of language models to predict company earnings results. See our methodology for detail and disclaimers. If you haven’t already subscribed, join investors and engineers interested in LLMs+investment research here:
Key takeaways
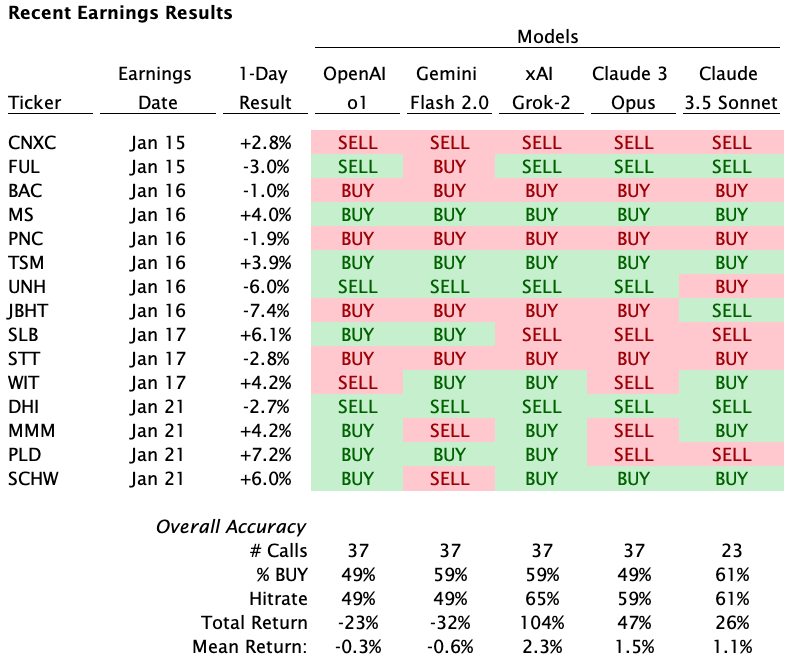
After 37 earnings results, Grok-2 still the most accurate model with a 65% hitrate and a mean return of +230 bps per earnings
Anthropic’s models are at ~60% hitrate and 110 - 150 bps mean return per earnings
Gemini and OpenAI are both slightly below 50% with slightly negative mean return per earnings
This represents a slight decline in performance for Grok and Anthropic and a slight improvement for Gemini and OpenAI vs the previous update
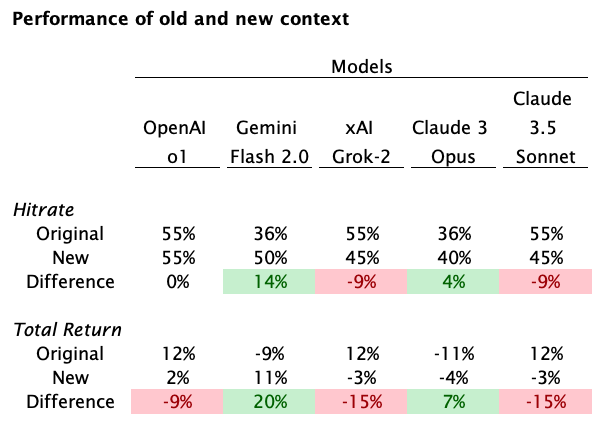
Our first attempt at feeding the models additional information led to decreased accuracy
Last week, we built a new version of the template for what company information we provide each model and have been running the two in parallel to see which is more accurate.
The new version added market commentary and additional historical quarters
Surprisingly, this “improved” context produced worse performance. We discuss theories below
Based on these learnings, we have developed “v3” of the context template and are running a new test to see if accuracy improves
The v3 template includes current and past institutional holders, which may have impact on post earnings price action
We are testing this new version in parallel and will roll it out once we see consistent performance improvement across most models
Recent earnings
More information —> less accuracy?
Our system feeds each model the same information (“Context”) when asking it to make a BUY or SELL call about a given company’s earnings. Our original Context template includes the following information for the past few quarters:
Share price performance vs the S&P
Press releases
Company and peer earnings transcripts
Sellside upgrades and downgrades
Share price performance during the quarter
Share price reactions from past earnings
Last week, we began testing an improved Context template that included the above plus:
Many more historical quarters of this information
Market commentary explaining key price moves in the most recent quarter
These changes led to decreased performance overall:
Two theories:
Some research shows decreased reasoning performance with longer context lengths. Adding additional historical quarters may have been counterproductive
Some research shows weaker models outperforming stronger models in trading decisions during bull markets, as weaker models tend to overweight subjective commentary:
“…stronger LLM tends to focus more on the facts while the weaker LLM give more weight to subjective news. However … the increased reasoning ability does not bring a higher return in the cryptocurrency trading. This outcome aligns with economic theory, which suggests that typical market participants are only partially rational, with investors driven by emotional and psychological factors that push asset prices far beyond stock’s intrinsic value…”
This is one possible explanation for the improvement in the lower performance models (i.e., Gemini and Claude Opus), but not the stronger models.
Next attempt: adding institutional holders, more market commentary, fewer quarters
Based on these learnings, we are testing a new context template in parallel:
Pulling in current and past institutional holders, often a factor in price action following earnings
We have again pulled in market commentary, though this time for all past quarters
Reducing the total number of historical quarters of information provided
We will compare the results in a future update.
Upcoming earnings
Note the following earnings estimates are derived from the original Context template, discussed above.

The reasoning behind these earnings calls are available here.
If you have feedback or would like to participate in this project, please reply to this email or reach out via X or LinkedIn.