

Flat Circle - o1 now best performing model
Plus: the models are correlated, Deep Research + Deep Research

Flat Circle measures the ability of language models to predict company earnings results. See our methodology for detail and disclaimers. If you haven’t already subscribed, join investors and engineers interested in LLMs+investment research here:
Key Takeaways
After 209 live earnings, o1 now leads with a 57% hitrate and 130 bps mean return per earnings, followed by Grok-2 at a 55% hitrate
57% is approximately 2 standard deviations away from random chance after 209 coinflips
The Gemini and Claude models appear to be approaching 50/50
The models are fairly correlated with each other, tending to make the same calls
We’ll have to figure out ways to ensure model orthogonality before institutions start adopting LLMs to make investment decisions
Recently spoken with a large number of readers and appreciate the helpful feedback
In addition to reporting on the leading language models and their ability to call company earnings, I plan to include other resources and news relevant to LLMs+investing
Model correlation
While the models show differing abilities, they are fairly correlated. LLMs are somewhat more likely to issue the same calls than if each model were merely flipping coins.
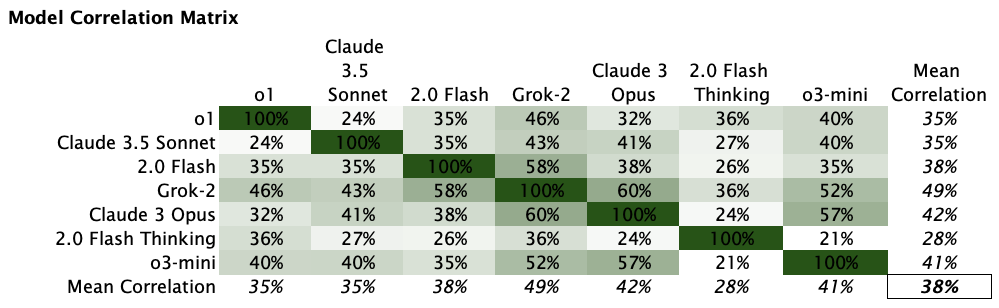
This makes sense as they likely share much of the same training data, technology and methodology.
This also means the prior basis of comparison of 5 models flipping coins was overly strict as we no longer talking about 5 independent models. After 209 earnings, o1’s hitrate is 57%. 2 standard deviations above the mean of a single coin flipper is 57% vs. 59% for 5 coin flippers.
I can’t deduce any patterns among why certain models are more or less correlated to others. Only thing I see is the two newest ‘reasoning’ focused models, o1 and Gemini Flash Thinking, appear least correlated with others. We’ll see if this trend continues.
Models’ orthogonality, the extent to which they are uncorrelated, will be a crucial dimension on capital allocators’ decisions to use them for trading decisions. Orthogonality across managers and market factors is essential for risk management and leverage.
Model accuracy


Comparison to other benchmarks

How does a model’s ability to call earnings compare to standard LLM benchmarks? We take each model’s reasoning score from LiveBench, and compare it with their hitrate and mean share price return on their ability to call live earnings.
The models with the best share price return are those with the highest and lowest reasoning scores. The models in the middle underperform.
“A lot of smart people think they’re way smarter than they are, and therefore they do worse than dumb people” - Charlie Munger
Upcoming earnings calls

I’m debating whether to continue listing these upcoming earnings calls at all, since the hitrates are so close to 50%. Even the hitrates where BUY or SELL calls are unanimous aren’t meaningfully more predictive. If these calls are valuable or you would like a different display of them, please let me know.
Industry news and updates
I’ve spoken to a lot of readers over the past couple weeks and am grateful for the feedback on this newsletter and the LLM systems we are building. If you and I haven’t spoken, please reach out!
For now, I plan to expand the scope of this newsletter to include news and resources generally relevant for the LLM+investors community. From this week:
OpenAI Deep Research + Open Deep Research. OpenAI released an new tool that’s helpful for investment research. It’s exhilarating to input a query, watch it conduct searches, consider the results, think of new queries and so forth. A few days later, David Zhang launched an open source version of Deep Research that already has 10K stars on GitHub. Excited to monitor development of these ‘research agents’ and their application to investing. Seems a model’s ability to reason is inextricable with its ability to research.
Model ML, LLM platform for PE and investment banks, announces $12m funding round. There have been dozens of these tools, but thought the description on their approach was interesting: “When you open Model ML, it looks a lot like Google Drive. It has its copycat versions of Excel, Powerpoint, Word, etc., which ensures that no information ever needs to leave the workspace.” Of course replicating Microsoft Office will be no small feat. But this approach seems similar to why OpenAI Deep Research is a better experience than OpenAI Operator. The fact that it’s fullstack means it can think around bottlenecks and get 10x as much done, instead of requiring the user to babysit.
Follow the progress of LLM investment research
If you have feedback or would like to participate in this project, please reply to this email or reach out via X or LinkedIn.